
The Complete Guide to Inference Caching in LLMs
ML Mastery Bala Priya C April 17, 2026
AI Summary— plain English for professionals
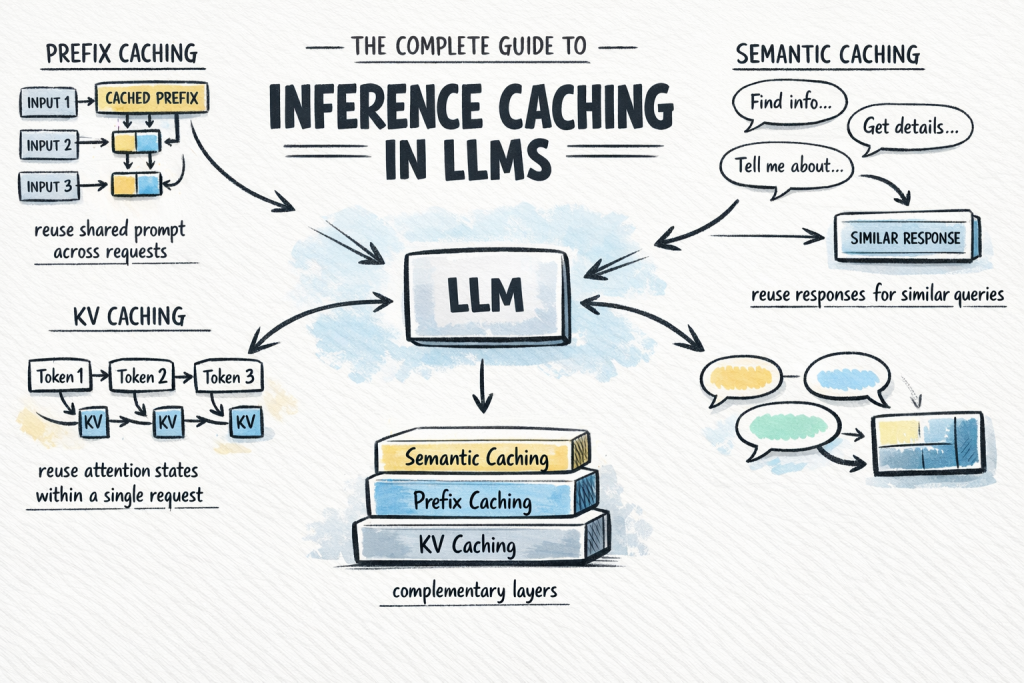
# The Key Insight Large language models cost a lot to run, especially when you use them repeatedly, so companies are adopting "inference caching"—a technique that saves the results of previous requests so you don't have to re-process the same information twice. Think of it like remembering answers you've already looked up instead of searching for them again every time. This can significantly cut costs and speed up responses for businesses relying on AI tools.
Calling a large language model API at scale is expensive and slow.
More from Learn AI



Get new guides every week
Real AI income strategies, tool reviews, and plain-English news — free in your inbox.
or enter email